Yesterday I tested out a method of exploring poetic diction in poetic corpora, using Geoffrey Hill’s opus up to 2012 [“Measured Words“]. I left several issues hanging in that post, which I thought I would follow up on today.
For one, I implied that there might be value in comparing the general picture or footprint of the graph to other corpora, e.g. of another poet. More generally the implication was that graphing word frequencies like this might be a productive way of exploring a poetic corpus. In that sense, finding much that (as a long-time close reader of Hill) I would expect to find serves as a confirmation that this method produces relevant outcomes, as much as it is an exploration of Hill’s word-fondness and unfondness.
Here I’ll do the same analysis with another poet whose work I know pretty well, both as a second check on the method and a first attempt to see what it might be able to tell us about one poet’s corpus as a whole vs. another’s. The corpus is Seamus Heaney’s Opened Ground (not a “collected”, but a “cull-ected”, as Heaney says – still, a good number of poems) plus the three trade collections that come after. The methodology is exactly as before, so I won’t repeat it here–see the original Hill post for details.
First, the “footprint” [click image, as always, to enlarge]:
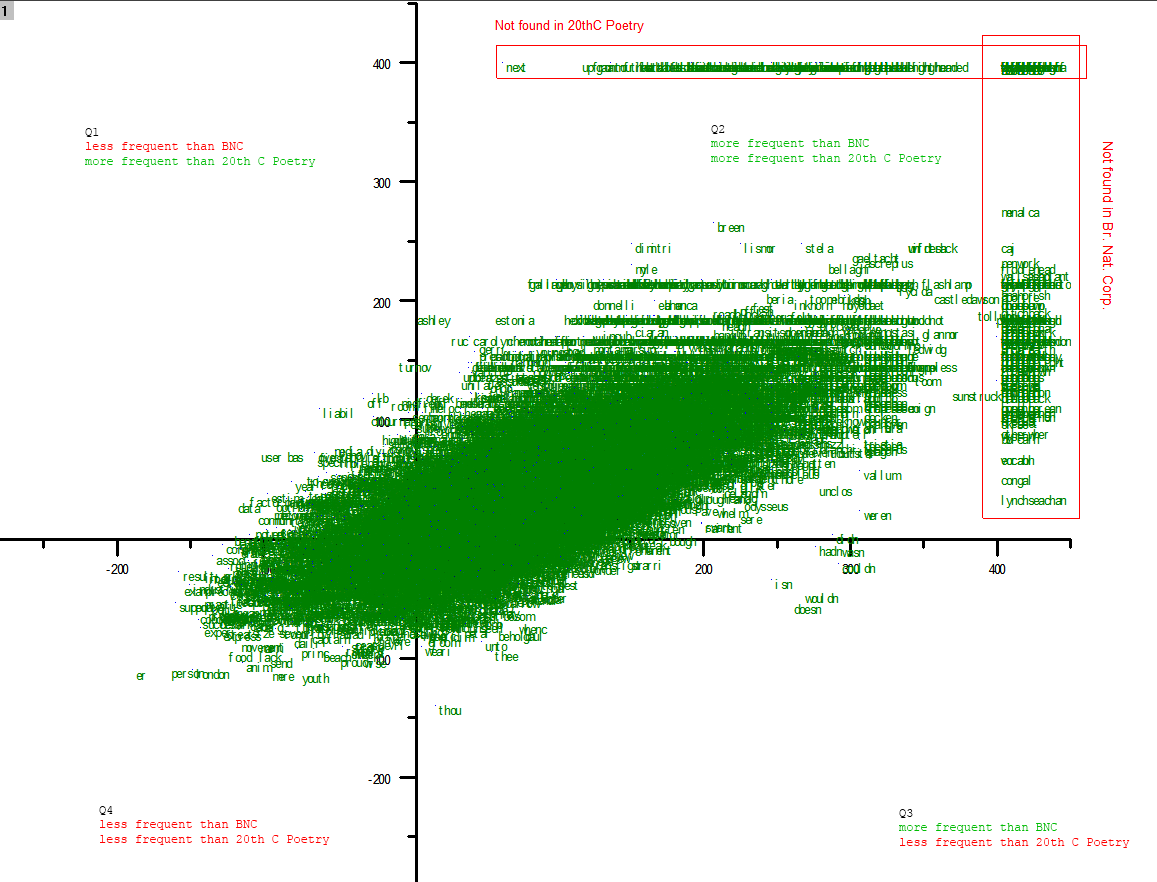
[click here to open a large version of the same Hill plot]
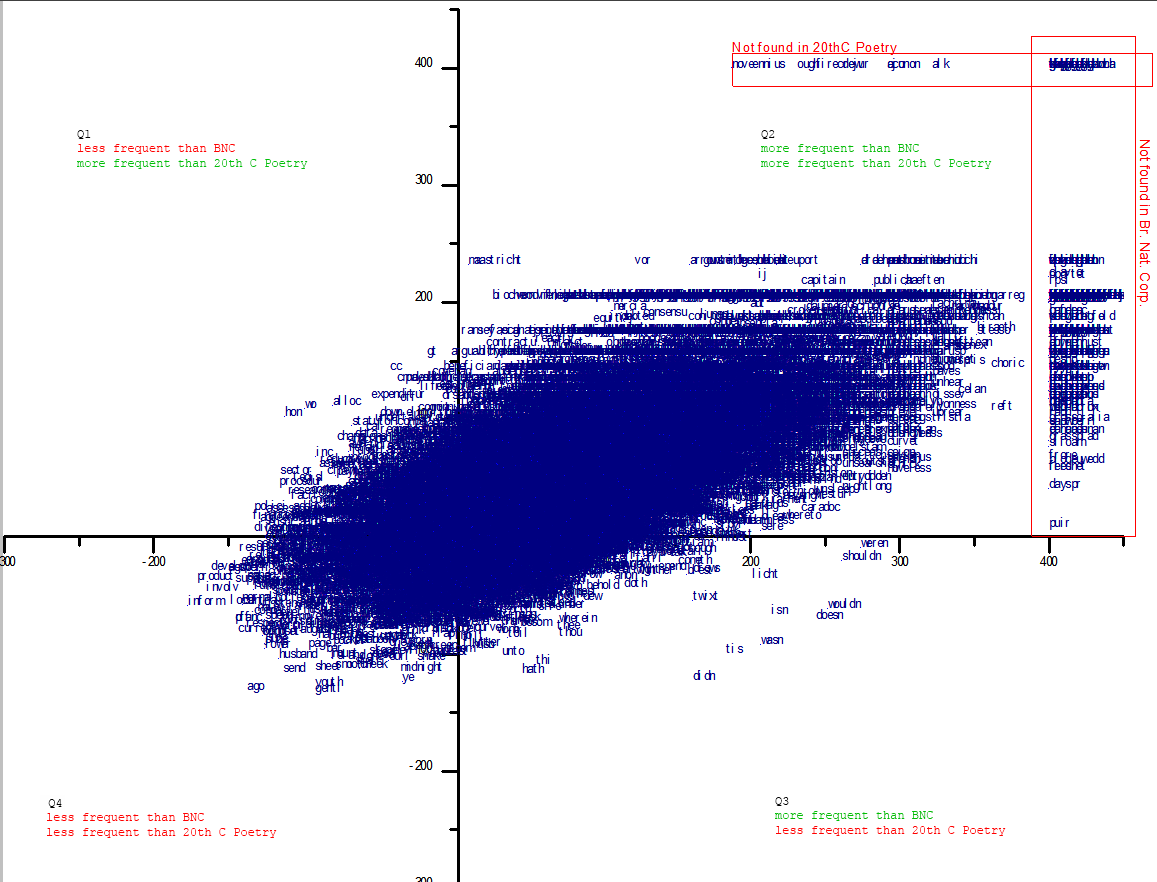{kind=link}
So far, so similar. There are fewer word tokens on this plot but they take on a familiar shape and inhabit roughly the same ranges. If there’s a noticeable difference, I’d say the Hill plot is just a little thicker around the middle.
Taking a quick look at the red-box radical outliers, I find that missing from the 20thC poetry corpus are forklift, lightheaded, and vitruvian; missing from BNC are slabber, ashless, dishabille, vocable; and missing from both (double red box) are draggiest, workshirt, seedbag. There are many more in each category. As before, some of these are foreign or dialect words, some are neologisms, some are spelling variations (note the missing hyphens in Heaney’s compounds) and some the artefacts of stemming or filtering algorithms. I’m fairly sure next, which you can see on the left end of the top box, has been used in poetry in more than one twentieth century poem. Speaking of artefacts, I notice in Q3 some of the contractions I saw in the Hill chart, which makes me suspect even more strongly that there’s a glitch in the filtering algorithm that I’ll need to chase down.
As mentioned last time, although poetic neologism and the use of very rare words is a topic of some interest, for this analysis we’re really more interested in words that are not very uncommon in either of the control corpus. One reason for this is the relatively small size of the poetic corpus–use any word only once and it has already occurred 28 times per million words in the Heaney corpus, about the same rate as twist, stir, and beam in the BNC.
So here is the same data, limited to word stems with a frequency of 50 wpm in both the BNC and 20thC poetry:
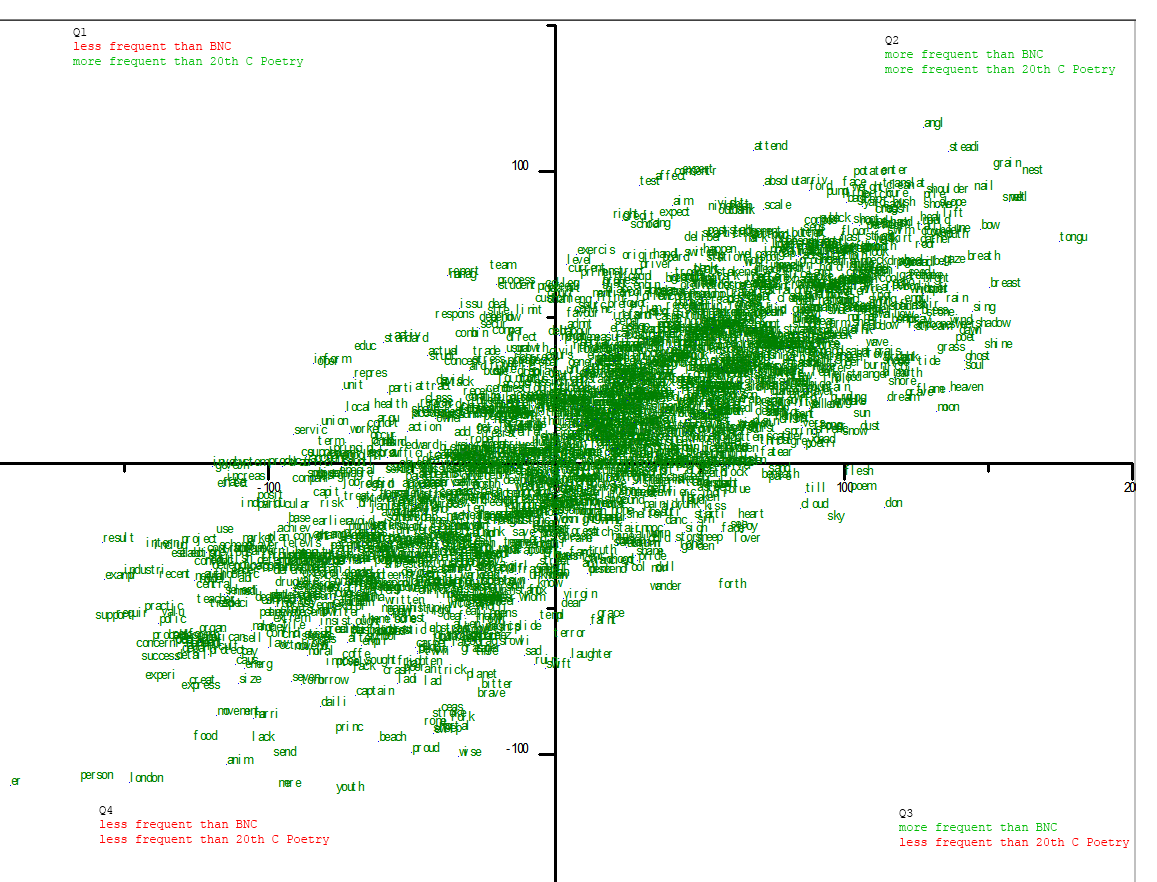
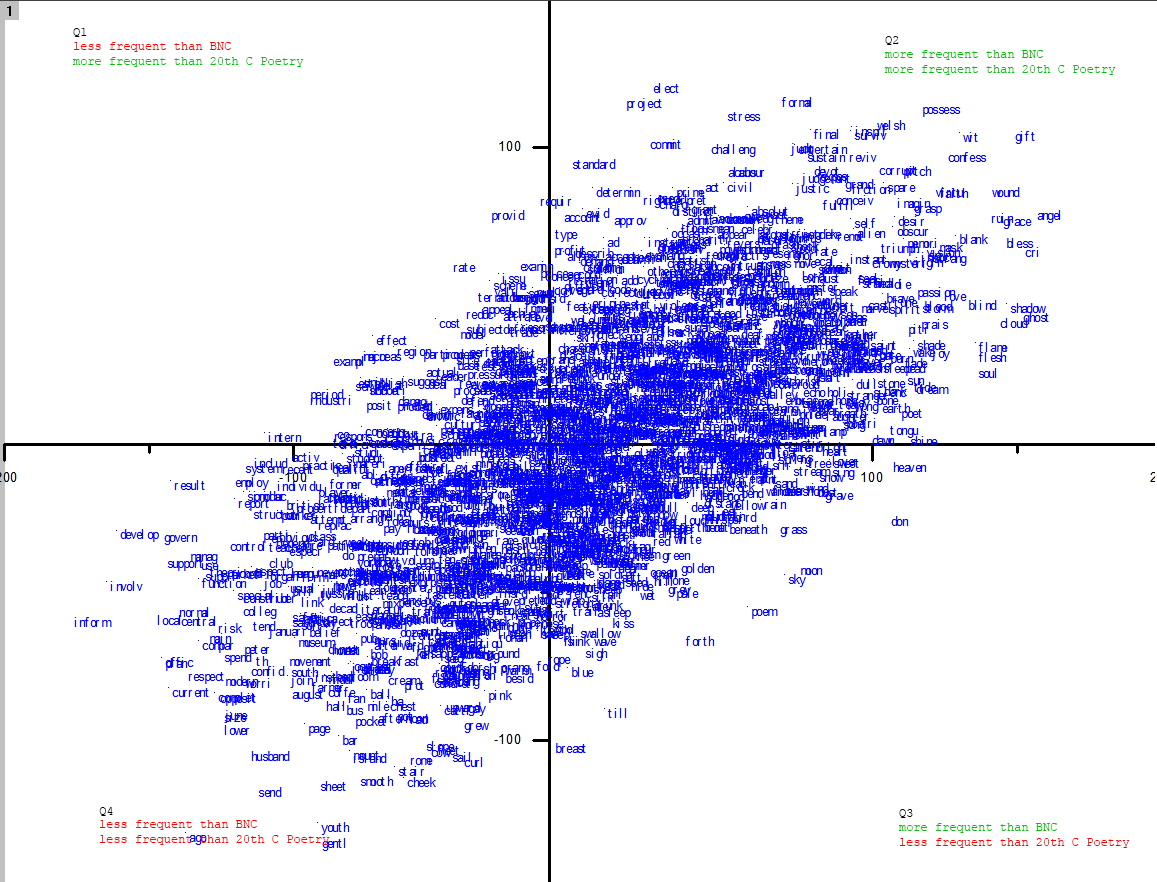{kind=link}
Once again the overall shape is very similar to the Hill chart. To my eyes the Hill looks to be shifted down and right towards the Q3 corner somewhat, tilted just slightly clockwise, and rounder overall (though still oblong). At first blush, then, it appears that this view of the data is not fantastic for comparing one poet’s work to another. In pursuing this, I’ll want to look a little closer at shift, tilt, and shape of the graphs that come up to see if there’s a real effect being displayed here or not. The next experiments will graph other genres of text.
Looking at the outliers, at first it’s strange to see youth and result in virtually the same position in both the Hill and the Heaney graphs. This implies that both poets use those word with roughly the same frequency. In fact they do: they use it both once, and because their corpora are of similar sizes, the word plots in roughly the same spot (Hill’s is a bit bigger, so they both plot a bit lower). A pitfall of small data, or a telling shared avoidance of key terms? This chart won’t tell you.
In terms of intuition confirmation, it’s nice to see london, person, food, and lack down in Q4; and far up in Q2, it’s a plus to see tongu(e), grain, nest, lift, rain, steadi(y), potato, and breath. Potato is a bit funny, though. Even funnier is that the Oxford English Dictionary cites Heaney for his use of this word in “Digging”: “The cold smell of potato mould,” etc.. “Potato, for God’s sake!” was his reaction when I mentioned this to him.
Back to the graph. To my mind, there are some slightly more surprising results here than potato: in Q1, we find that Heaney uses servic(e), union, local, health, team, and educ(ation) far less than common usage, which is to be expected, but somewhat more than is typical for 2othC poetry. Do these represent distinctive themes for Heaney? Or are some of these mixing apples and oranges? There are likely a few senses of union getting conflated here. Team I checked out in the poems – three times (of twelve) it refers to a team of horses. But health I think must be comparable across corpora. Ditto local, though seeing it close to union threw me for a second.
Below I’ll reproduce the same four close-ups as I did for the Hill analysis. Have a look and let us know in the comments if anything pops up as either expected or unexpected.
Most statistically overrepresented word stems (top Q2) [click to biggen]:

{kind=link}
Most statistically under-represented word stems (bottom Q4):

{kind=link}
Most over- and under-represented compared to common usage, but typical of 20thC poetry:
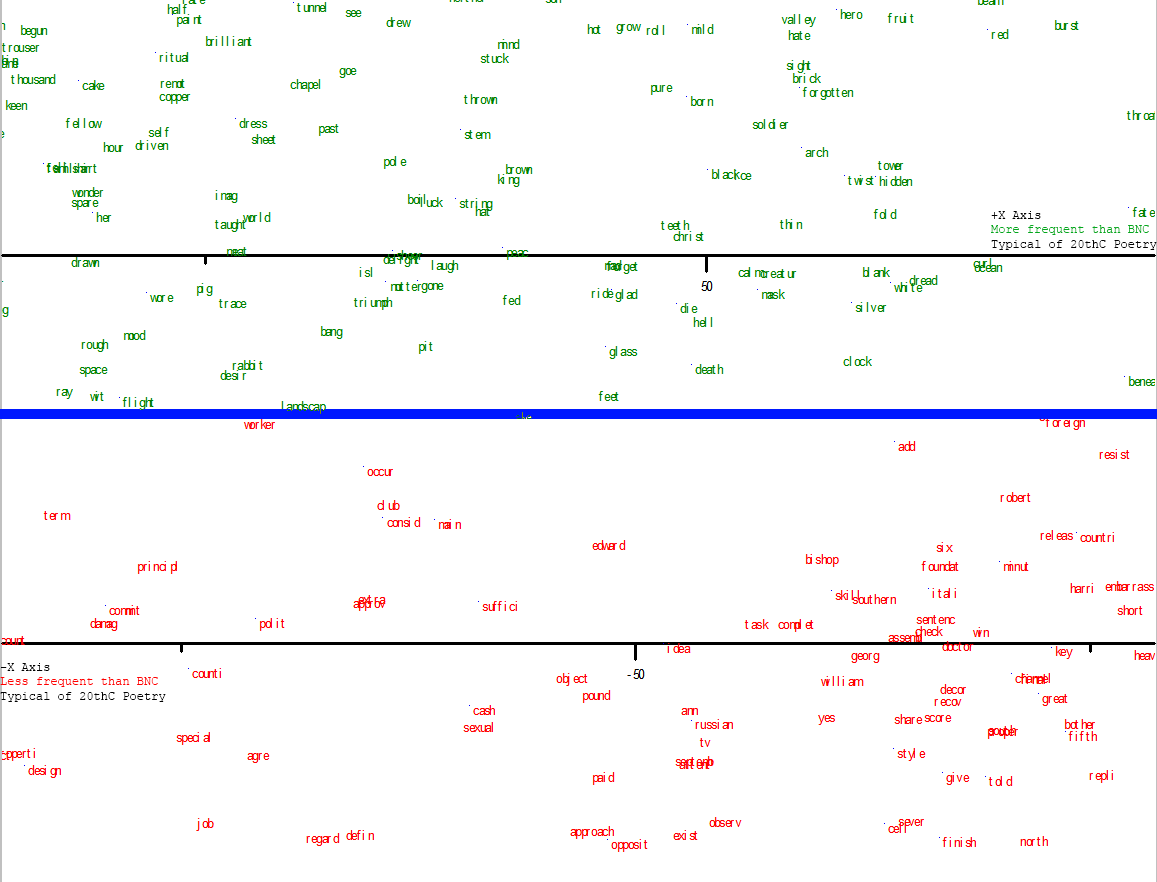
{kind=link}
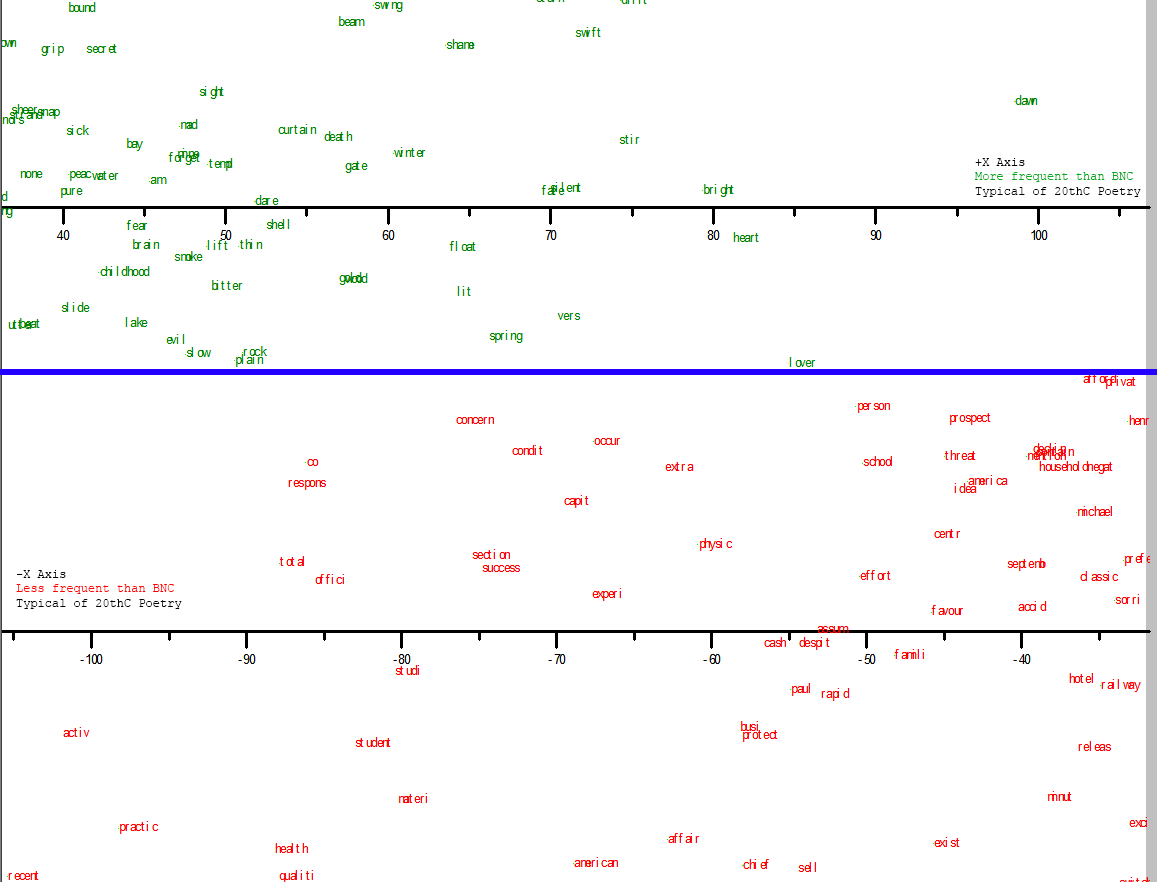
Most over- and under represented compared to 20th C poetry, but typical of common usage:

{kind=link}
[…] things in literary works or big corpora to inform analysis. I have even done it myself (here, here, here, and plenty elsewhere), in a much less sophisticated way than Dalvean does. But I’ve […]