In “Measured Words” I made an assertion that “some words aren’t very common in speech but show up fairly frequently in poetry, and vice versa.” This is intuitive, but I’m going to demonstrate it anyway, to make good my other assertion that “seeing what you already know or think you know displayed in an unfamiliar way is not a trivial kind of confirmation.”
It might be worth trying to guess for a moment what words might be disproportionately common in poetry or in common usage. Something like “moon” for poetry, maybe, and “profit” for the everyday? Take a moment to think of some more before we have a closer look.
Okay, here’s the methodology-skip this paragraph if it bores you. First I took all the word stems in the British National Corpus and a large corpus of 20th century poetry and got their frequencies in each corpus. I removed stems with a frequency of less than 5 wds per million (wpm). Then I selected all the stems that had a frequency in one corpus of at least twice the other, to eliminate clutter. Then I simply plotted each word stem to its two frequencies, with frequency in poetry on the Y axis and frequency in the BNC on the X. The result looks like this: [click to enlarge]
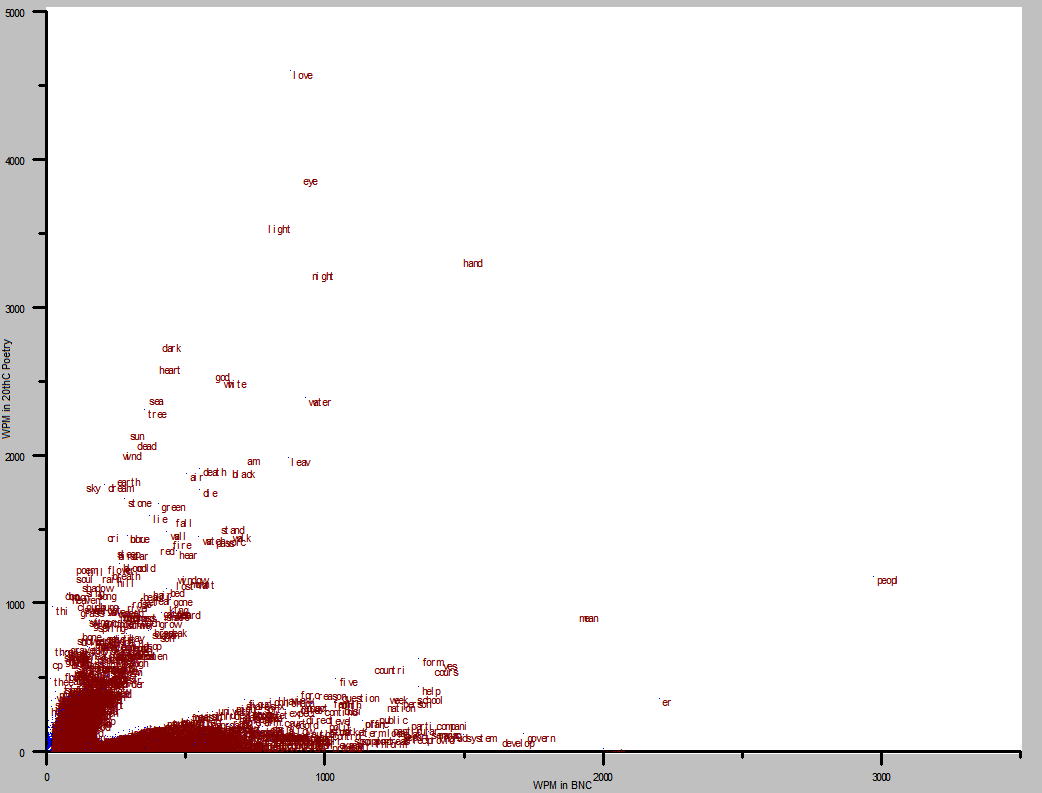
The split that you see rising diagonally is partially an artefact of having filtered out words with frequency pairs within 2x of each other (the 45 degree line represents a 1:1 frequency ratio).
Once again our eyes are drawn toward the outliers. Once again, ideally, these should contain a mix of unexpected and expected results. Finding love, eye, and light in the top half of the graph is no big surprise, but it does give us some confirmation that the chart is not totally misrepresenting the data. We might also notice a bunch of rhyming words in the top two thirds of the graph, compared to the right-hand two thirds, which also stands to reason [note to self: this can be measured algorithmically].
It’s important in exploring this chart to remember that it is giving raw frequencies. That means that while love is a long way away the most frequent word in 20thC poetry, it is also fairly frequent in the BNC. The relative frequency is only about 5.2x. In order to focus in on under- and overrepresented words in each corpus, we want to explore the areas close to one axis, and far from the other.
So, in the graph below I’ve isolated words that are between around 10x and 55x more common in 20thC poetry than they are in the BNC, looking at the less-common end of the BNC (x) scale:
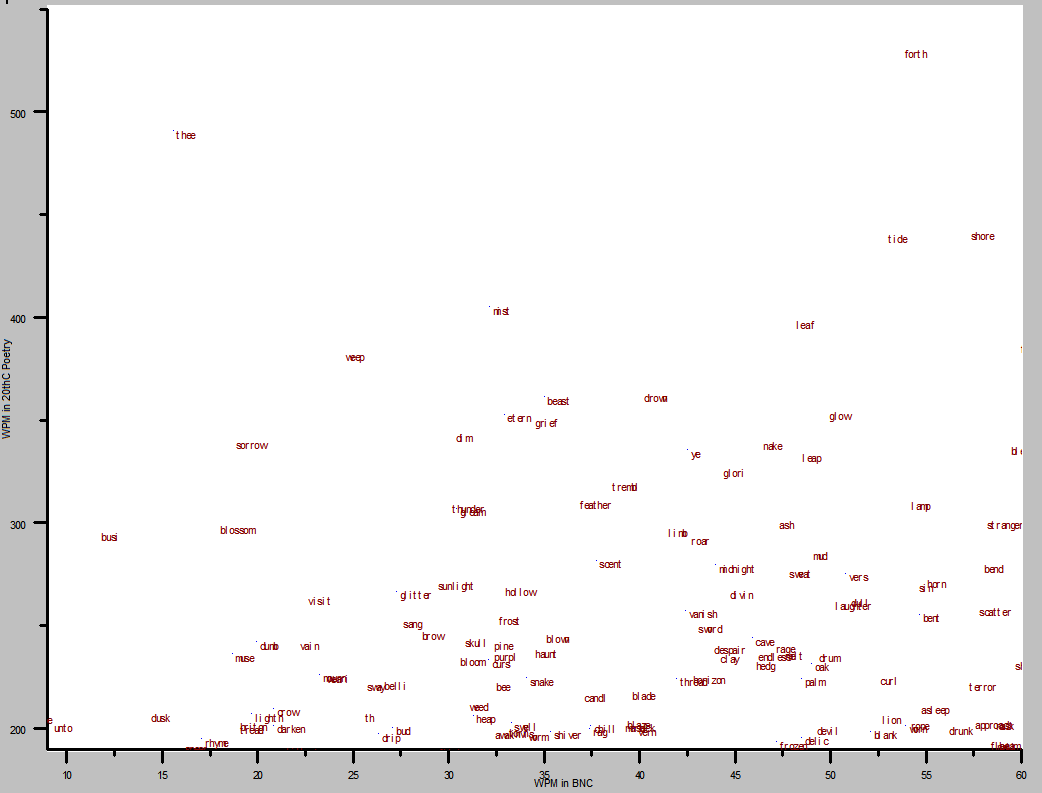
Finding unto in the bottom left corner (about 22x) is not at all surprising, nor is thee up at the top left (32x). I’d want to investigate busi (I assume the stem of busy and business), since I’d expect both long-form words to be further along the X axis.
Next, the opposite scenario: words that are much more common in BNC than in poetry (ranging from about 30x to 500x):
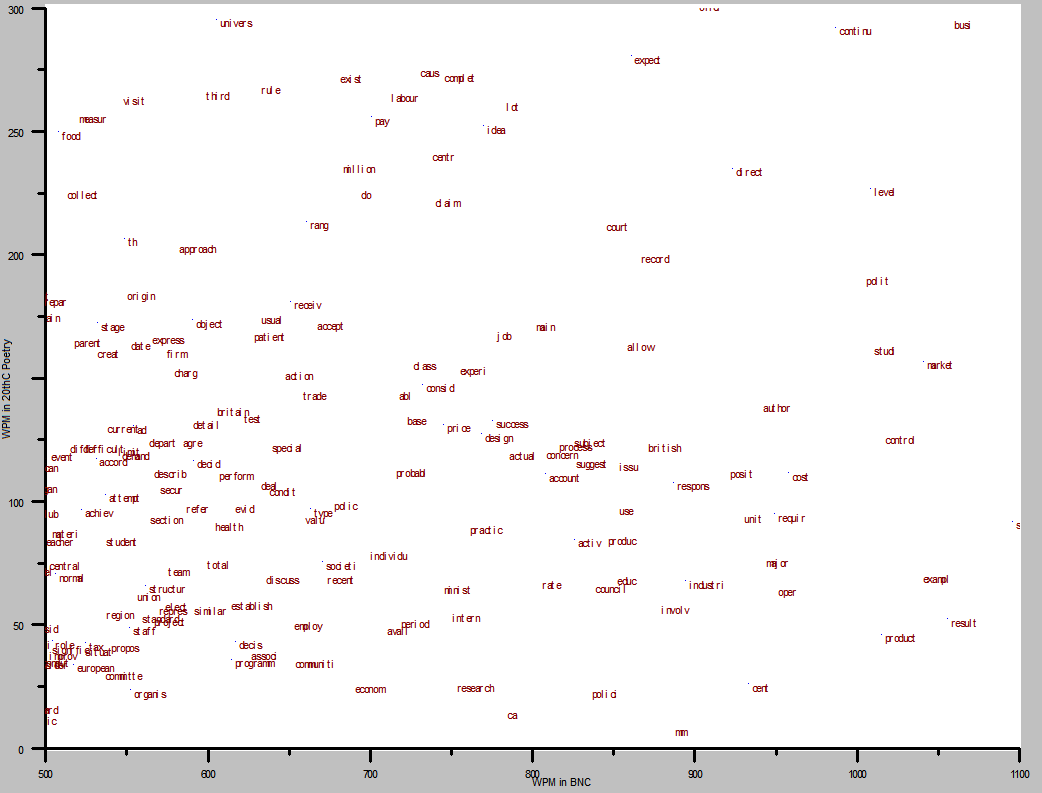
Nice to see organis [stem for organize, organization, organized, etc], econom, research, and polici down near the bottom (where they belong!).
Peeping around this graph convinces me that my intuition about diction is basically right, and more importantly for my previous graphing technique, can be modelled. That is, this is confirmation that measuring a particular corpus’s poetic diction against both the large poetic and the general corpora is appropriate, and that the resulting numbers conform to my “domain knowledge” (i.e. education). This gives me confidence that when I do come across something surprising, it will be due to the data, and so interesting, not the model, and so irrelevant and misleading.
Maybe the graphs also tell us something about the poetic value of particular words. Maybe not. A while ago I did a different kind of analysis, using a different idea of “poetic” words, by counting up which words had the greatest proportion of usage evidence from poetic sources in the Oxford English Dictionary [see “Discovery: the Most Poetic Word in the English Language“]. That was half-serious, but there’s a serious point in there, applicable to these graphs here, about the blind equating of frequency with significance.
This is interesting. We don’t look at language data often enough. One question I had was what percentage of words were limited out when you isolated the those with disproportionate frequencies? Was it 95% of words, meaning that poetic and non poetic diction are actually highly similar and this is an analysis of outliers, or was it something much greater like 50%?
There are actually three stages of filtering (or isolation) going on. The first happens in the preparation of the corpus and involves taking out the commonest words in the language (prepositions, articles, etc.) and then stemming all the words (reducing the number of tokens considerably).
The second removes extremely rare words in the corpus – those with frequencies of less than 5wpm (many of these are OCR errors etc).
The third takes out words that have BNC:Poetry ratios between 0.5 and 2. This just removes a wedge from the middle of the graph, since I wanted to look at the outliers anyway.
But to answer your question, the final step reduces the number of stem tokens from 9224 to 5189, i.e. by about 45%. Reducing the frequency threshold to 1 wpm brings the total up to 20,110.
Thanks for responding and sharing your analysis.
To give an idea, here’s a selection of word stems with frequencies of 1-2 wpm in the BNC: stoicism, pinto, breathable, lingo, tamp, discomfit.
A different kind of analysis would look at just the rarer words along the same axes.
Thanks for the comment. It has got me thinking that the title of the post probably ought to have been “How is poetic diction different?”, since by design I’ve excluded the area in which it is the same.
That would make sense, or perhaps step down from the big/overall picture to the differences. Either way, interesting and important analysis.
[…] things in literary works or big corpora to inform analysis. I have even done it myself (here, here, here, and plenty elsewhere), in a much less sophisticated way than Dalvean does. But I’ve done it […]
fantastic! great stuff. i was wondering – i’vebeen talking with a friend about a similar undertaking… what did you use for your corpora? the 20th c. poetry has been a hard one to find aggregate data for… & data from separate communities would be even more fascinating, & useful for considering regional & national differences, language, style, etc. E.g, Southern-US poetry & everyday usage may run more closely together than everyday-southern-US and everyday British. Props.
[…] related discussions, see “how different is poetic diction“, “Seamus Heaney in Between“, “From London to Potato: Seamus Heaney in […]