I’ve written a little program that annotates texts according to how much the Oxford English Dictionary cites them. This lets you see how different parts of a work have factored in the compiling of the dictionary – as if you were looking at the text through the collective eyes of all the OED readers, lexicographers, and editors over the last 130 years or so.
When the OED was first made available in electronic form in 1989 [*I distinctly remember hearing about the CD ROM release on NPR – I was ten years old], one of the most impressive things must have been the ability to search the dictionary using parameters other than the alphabetic placement of the headword. One could, for the first time, find something like, “all words which have citation evidence from Paradise Lost,” for example.
Since then, if you have more than a passing interest in the OED, you’ve probably used the online “Advanced Search” function, which allows all sorts of queries of OED data. Here, for instance is a screen-shot of what the current OED3 online interface gives for a search of “Paradise Lost” in the quotation title:
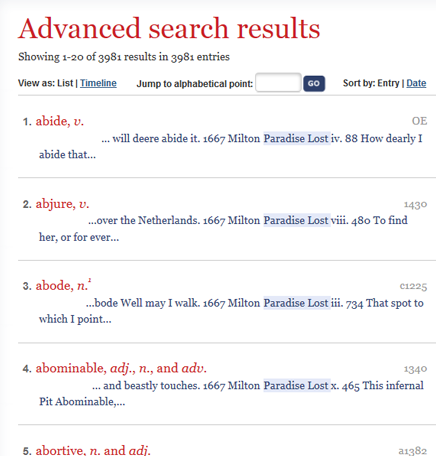
This gives all sorts of useful information about the contribution of Paradise Lost to the formation of the OED. Almost 4,000 citations is a lot for one work. Further restrictions would allow you to see all the first citations: usages first attested in this work.
However, even though line numbers are given, because the list is ordered alphabetically by the headword (again), what it doesn’t show very well is what parts of the source text were most important to OED readers and lexicographers, or how important individual parts were, or how these parts relate to one another in the original context. In “Quotation Economy in the OED” I tracked down quotations that were used more than once in OED. That was kind of interesting, but it only counted exact matches, ignoring partial overlaps and even small textual variations.
So in the last couple of days I’ve ginned up an OED “quotation recontextualizer,” which marks up the source text according to how thoroughly it has been excerpted in OED. Naturally it’s going to be most interesting for the few hundred works that are heavily quoted. The first few runs of this have been illuminating.
Below, for instance, is a screen-shot of first few lines of Paradise Lost, re-annotated as it were by the collective effort of all OED readers and lexicographers. The intensity of the highlighting and underline indicates how many different headwords that particular string appears under, and the headwords are given in mouseover text (in the HTML file – the screen shot is static: see here for the full text of Paradise Lost, re-annoated):

This shows that the famous first phrase appears once in OED, but the more densely highlighted one appears three times, under “death, sb.”, “taste, sb.”, and “woe”. The last bit of that string (“and all our woe”) only appears under “taste” and “woe”, which is why it’s a little lighter. The program does fuzzy searches, which is necessary because of transcription errors and type-os in OED, errors in the digitized source text, and variant editions used by OED. It has some limitations – right now it doesn’t show elisions very well, so some of the overlaps can be confusing. I hope to improve that aspect, and add other bells and whistles, such as annotations for first word citations, first sense citations, and so on.
Fun? Explore all of Paradise Lost by clicking here, mousing over highlighted bits to get the OED headwords they illustrate.
I’ve done a few other runs for even more exploration. Clicking here will get all of Shakespeare’s sonnets (1609). Fuzzy matching was especially important for Shakespeare, since different editions were used by OED, introducing lots of spelling variations (v for u, for instance, as in the 1609 below).
A screen-shot of Sonnet 3 shows how WS gets for”uneared”, among other beguiling words:

No Comments