With all the recent news talk about metadata, it’s worth remembering that so-called big data is useless without good algorithms to parse and analyse it, and rich metadata to guide us through it. In addition to various versions of OED [which has great metadata], the biggest datasets I access regularly are Google Books and Google Scholar, either to find data I’m interested in or to do rudimentary meta-analysis (via N-gram viewer, e.g.).
I’ve discussed some basic problems with drawing conclusions from these datasets before, especially regarding the lack of metadata on genre, or type, of book. Long ago, Geoff Nunberg catalogued serious problems with the results of automatic metadata generation, in Google Books: A Metadata Train Wreck.
The good news is that the algorithms are greatly improved since Nunberg’s post, and continuously improve themselves, as well as the metadata. A recent example concerns yours truly. Here below is a screenshot of a journal article that was recently archived by Google Scholar. Pretend you are an algorithm. Your task is to identify the author and title of the article:

Because you are a human familiar with the conventions of print, I’d be willing to bet that you correctly extracted the relevant metadata from this bit of text. Can you explain how you did it, in a way that could be adapted to all printed texts?
Neither can Google, but it’s learning. Until several weeks ago, if you looked up the keyword “poetic antagonyms” in Google Scholar, you would have been given a choice among:
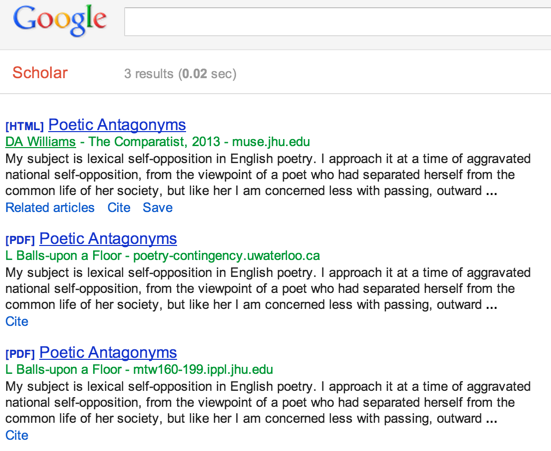
As a nom de plume, one could do worse than L. Balls-upon a Floor […my father’s people are of the Maine upon a Floors, whereas on my mother’s side we’re Kentucky Ballses … “Like,” as a forename, is a bit odd – perhaps it’s best understood as a diminutive of Puritan virtue name Love?]. Here, for kicks, are the several citation styles Google recommends (HT myl):

This has been fixed, I think: the attribution to Prof. Balls-upon a Floor no longer shows up on Google Scholar, though it can still be accessed via a legacy link I created at the time. Somehow a Googlebot came around and cleaned up the mess a previous Googlebot made.
It’s an interesting puzzle to try to work out what exactly in the algorithm that was trained to identify author names caused it to produce this silly result with this particular text. Perhaps was the first line ignored (or misclassified – as the publication title?) because author names tend to come below the title in most publications? But surely even in that case “Isaac Rosenberg” ought still to have seemed more likely than “Like Balls-upon a Floor”? And how did Googlebot Two know which of Googlebot One’s three classifications were wrong, and which right?
via TW:

I felt a cleaving in my mind
I felt a cleaving in my mind
As if my brain had split;
I tried to match it, seam by seam,
But could not make them fit.
The thought behind I strove to join
Unto the thought before,
But sequence ravelled out of reach
Like balls upon a floor.
Emily Dickinson
(I’m currently in a chilly room with a tiled floor; “balls upon a floor” is a scrotum-tightening phrase to me. Out of reach, indeed.)